| images | ||
| .gitignore | ||
| docker-compose.yml | ||
| README.md | ||
Clickhouse guide
Clickhouse - очень мощный инструмент. Это высокопроизводительная база данных, которая обладает большим спектром возможностей. Хорошо подходит для построения отчетов и хранения истории.
Скачиваем урок
git clone https://git.rinsvent.ru/lessons/clickhouse.git
Запустить контейнер
docker compose up -d
Подключаемся через PhpStorm к базе
Ищем список драйверов
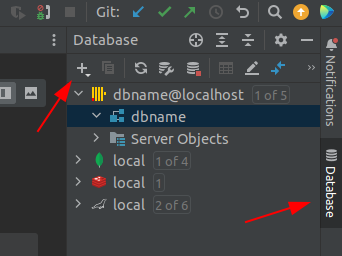
Выбираем драйвер
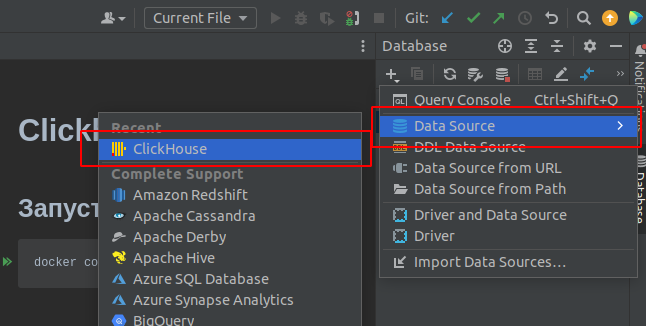
Указываем доступы до базы
Доступы можно взять из docker-compose.yml
- Логин - dbuser
- Пароль - dbuser
- Имя базы данных - dbname
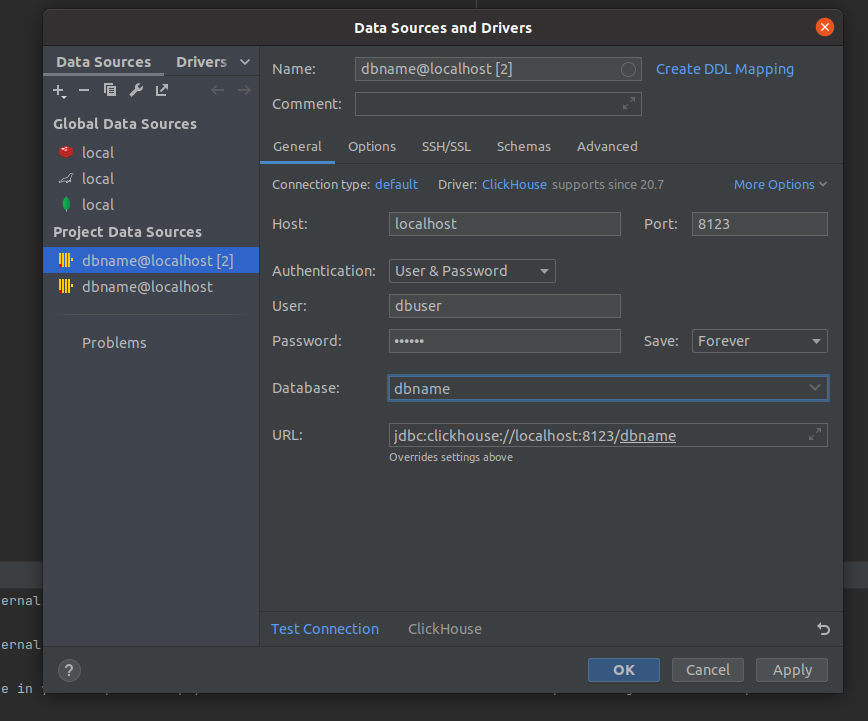
Переходим в терминал
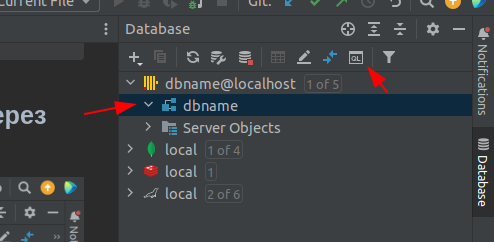
Выбираем дефолтную консоль
Создание таблиц
В целом clickhouse реализует sql и запросы похожи не те, которые используются при работе в mysql, но есть ряд отличий(с ними познакомимся дальше). Создание таблицы может выглядеть так
CREATE TABLE history
(
uuid UUID,
entity ENUM('user', 'device'),
entity_id String,
action Int16,
field String,
value Nullable(String),
created_by Int32,
created_at DateTime
)
Engine MergeTree()
PARTITION BY toYYYYMM(created_at)
PRIMARY KEY (created_at, uuid)
ORDER BY (created_at, uuid);
Нужно скопировать запрос в терминал и выполнить (ctrl + enter)
В данном случае мы создали простую таблицу для хранения истории В clickhouse нет auto increment поэтому в качестве primary key используется uuid. В данном случае создана партицированная таблица с разбивкой по месяцам, поэтому мы обязаны при создании добавить поле в PRIMARY KEY и ORDER BY Партиции позволяют ускорить запрос за счет того что выборка получается меньше по размерам. Вместо 1 большой таблицы на 10 миллионов записей, можно получить 10 виртуальных таблиц по 1 миллиону. При запросе к такой таблице clickhouse может перенаправить запрос только в нужные партиции тем самым избежав обхода лишнего количества данных. С точки зрения использования запрос не меняется. Мы по прежнему работаем с 1 таблицей. Всю магию по определению партиция и объединению результатов выборки clickhouse реализует под капотом. За счет этого, запросы получаются быстрее по сравнению с классической single таблицей.
По sql выше мы видим, что определение типов в запросе выглядит иначе по сравнению с mysql. Информацию по типам можно найти в официальной документации в этом разделе https://clickhouse.com/docs/ru/sql-reference/data-types/int-uint. Наиболее явное отличие это определение nullable - оно связано с типом в отличие от mysql.
Дальше в запросе видно, что мы указали engine для таблицы. В отличие от mysql, где на проекте обычно используется всегда один движок, в clickhouse нужно иметь понятие об их существовании и отличиях. Официальная документация тут https://clickhouse.com/docs/ru/engines/table-engines. Каждый движок несет свои уникальные возможности. Например:
- MergeTree - позволяет использовать партиции и быстро обрабатывает insert запросы
- MySql - позволяет делать запросы к mysql через clickhouse и тем самым избежать дублирования данных
- File - позволяет писать / читать из конкретного файла. Может быть удобно для просмотра логов, либо для быстрого импорта данных в основную таблицу на основе которой уже выводится статистика.
Модификация полей таблицы (DDL)
Модификация полей в целом аналогична mysql Выполним запрос и описание таблицы
ALTER TABLE history MODIFY COLUMN created_by Nullable(Int32)
Посмотрим DDL
 Видим такой результат
Видим такой результат
-- auto-generated definition
create table history
(
uuid UUID,
entity Enum8('user' = 1, 'device' = 2),
entity_id String,
action Int16,
field String,
value Nullable(String),
created_by Nullable(Int32),
created_at DateTime
)
engine = MergeTree PARTITION BY toYYYYMM(created_at)
PRIMARY KEY (created_at, uuid)
ORDER BY (created_at, uuid)
SETTINGS index_granularity = 8192;
Текущая схема соответствует ожидаемой структуре.
Вставка данных
Вставка данных похожа на mysql. Выполните в терминале
insert into history SELECT generateUUIDv4(), 'user', generateUUIDv4(), rand32(), 'first_name', 'Anakin', 3, now() - interval 100 day;
insert into history SELECT generateUUIDv4(), 'user', generateUUIDv4(), rand32(), 'last_name', 'Skywalker', 2, now() - interval 50 day;
insert into history SELECT generateUUIDv4(), 'user', generateUUIDv4(), rand32(), 'age', '33', 1, now() - interval 10 day;
insert into history SELECT generateUUIDv4(), 'user', generateUUIDv4(), rand32(), 'first_name', 'Denis', 2, now();
Данные должны успешно вставиться и быть доступны на чтение Сейчас можно посмотреть какие партиции созданы Выполним запрос
SELECT
partition,
name,
active
FROM system.parts
WHERE table = 'history';
В ответе будет примерно такое
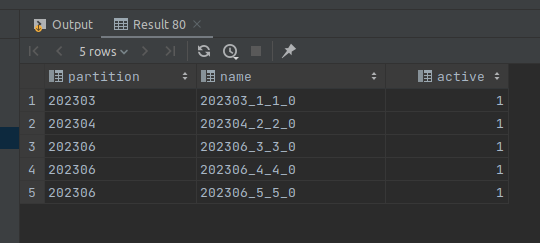
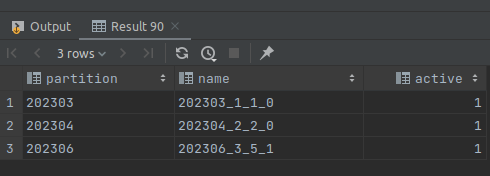
Здесь видно, что данные разбиты на 5 частей, несмотря на то что у нас три записи попадают в один месяц. При вставке clickhouse вставляет данные в отдельные куски и затем в фоне может их обрабатывать и объединять для оптимизации. По окончанию мы увидим следующий результат
Сейчас можно попробовать вставить такие данные
insert into history SELECT generateUUIDv4(), 'device', generateUUIDv4(), rand32(), 'first_name', 'Denis', null, now();
Вставка происходит успешно. Несмотря на то, что мы передаем null в not nullable поле created_by. В данном случае значение привелось к 0 и сохранилось в базе А теперь попробуем вставить такие данные
insert into history SELECT generateUUIDv4(), 'device2', generateUUIDv4(), rand32(), 'first_name', 'Denis', 3, now();
clickhouse выдает ошибку, что значение enum нам не известно и возвращает ошибку.
Модификация данных
В clickhouse нет классического редактирования данных. Отказ от update позволяет clickhouse быть таким быстрым. Но не все безнадежно. Если нельзя но очень хочется, то есть механизм мутаций. Подробнее тут https://clickhouse.com/docs/ru/sql-reference/statements/alter#mutations В целом это выглядит как редактирование на mysql, но через alter table
alter table history update value='Dionis' where value='Denis';
В данный момент возможно посмотреть список мутаций так
SELECT
mutation_id,
command,
is_done
FROM system.mutations
WHERE table = 'history';
В ответе будет такое
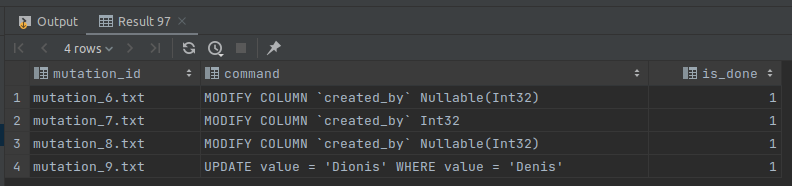
Из таблицы видно, что наш запрос был зарегистрирован в списке мутаций и что он уже выполнился. Особо сложные запросы могут выполняться часами. Такое обновление происходит асинхронно в фоне и не блокирует работу таблицы. Также можно заметить что изменения типа полей таблицы также были зарегистрированы в мутациях. Несмотря на то, что есть возможность редактировать данные, не стоит этим злоупотреблять. Если единовременно будет много мутаций в обработке, то это плохо скажется на производительности системы и может привести к ошибкам накатки мутаций. Мутации следует использовать когда одним запросом можно привести данные к ожидаемому результату. Например, на основе одного поля рассчитать значения другого или скопировать значения поля из соседней таблицы в указанную.
Вероятно, что может понадобиться возможность частого обновления данных. В этом случае есть несколько лайфхаков. Подробнее тут - https://habr.com/ru/companies/just_ai/articles/589621/ Один из простых способов достичь нужного нам результата выглядит так.
- Создаем еще одну таблицу где мы будем хранить более свежие значения полей
- Строим запрос с проверкой на наличие свежей версии значения
- Раз в определенный период (например раз в месяц) выполняем мутацию на перенос значений в основную таблицу и чистим значения из дополнительной
Создаем таблицу
CREATE TABLE history_value
(
uuid UUID,
value Nullable(String),
timestamp Int64
)
Engine ReplacingMergeTree()
ORDER BY uuid;
Обновляем значение
insert into history_value (uuid, value, timestamp) VALUES ((select uuid from history where field='age' and value='33'), '44', toUnixTimestamp(now()));
Получаем строки с актуальными значениями
select
uuid,
entity,
entity_id,
action,
field,
coalesce(hv.value, h.value),
created_by,
created_at
from history h left join history_value hv on h.uuid = hv.uuid;
Обновляем значение повторно
insert into history_value (uuid, value, timestamp) VALUES ((select uuid from history where field='age' and value='33'), '55', toUnixTimestamp(now()));
После повторно операции видим, что у нас дублируются записи

Можно было бы остановиться на первом варианте запроса с актуальными значениями, если допустимо, что какое-то время данные будут дублироваться. Например, если выполнить обновление ночью, то к утру, вероятно, что лишние данные уже будут дедублицированы. Чтобы ускорить процесс слияния кусков, можно принудительно запустить внеочередное слияние так:
Предлагаю пока не выполнять этот запрос, а продолжить изучение дальше. По окончанию практики можете повторить выполнить вставку нескольких строк данных и оптимизацию таблицы самостоятельно.
OPTIMIZE TABLE history_value DEDUPLICATE;
Если же запрос выполнили, то вставьте еще несколько строк
insert into history_value (uuid, value, timestamp) VALUES ((select uuid from history where field='age' and value='33'), '66', toUnixTimestamp(now()));
insert into history_value (uuid, value, timestamp) VALUES ((select uuid from history where field='age' and value='33'), '77', toUnixTimestamp(now()));
Подбедить дубли в realtime можно, например так:
select
h.uuid,
entity,
entity_id,
action,
field,
coalesce(hv.value, h.value),
created_by,
created_at
from history h
left join history_value hv on h.uuid = hv.uuid
left join history_value hv2 on h.uuid = hv2.uuid
where empty(hv.uuid) or (hv2.timestamp < hv.timestamp);
Так как для таблицы использовался движок ReplacingMergeTree, то дубль значения будет удален автоматически.
Раз в определенный период можно запускать миграции для чистки лишних значений. Синхронизируем значения
alter table history update value=(
select coalesce(hv.value, h.value)
from history h
left join history_value hv on h.uuid = hv.uuid
left join history_value hv2 on h.uuid = hv2.uuid
where history.uuid = h.uuid and (hv2.timestamp < hv.timestamp)
)
where uuid in (select distinct history_value.uuid from history_value);
И после этого удаляем лишние значения
alter table history_value
delete where timestamp <= (
select max(create_time)
from system.mutations
where command like '%UPDATE history%' and is_done = 1
);
Удаление записей
Здесь ситуация аналогична update.